
Tabla de contenido0
Los museos y bibliotecas atesoran nuestra herencia cultural. Pero, ¿qué pasaría si pudiésemos consultar toda esta información conjuntamente y no fuera necesario acceder a cada web o visitar personalmente cada institución? Y ¿si pudiéramos enriquecer otra información como el turismo, la educación… con toda esta herencia cultural?
Sólo en España existen más de mil museos y más de seis mil quinientas bibliotecas. La gran mayoría tienen su catálogo disponible al público a través de sus propias páginas web. Nos permiten conocer los fondos de los que disponen pero nos obliga a recorrer una gran cantidad de páginas buscando la información deseada. E incluso, debemos acudir de forma personal al museo o biblioteca cuando los fondos no han sido previamente digitalizados.
Ahora, imaginemos por un momento a un investigador trabajando sobre la toponimia de una palabra. Como ejemplo utilizaremos “El muelle del cay”; recientemente estudiada en la obra “El muelle del cay de Santander”, donde se hace un estudio de la relación entre la palabra muelle y cay. Ambas palabras significan lo mismo pero se han utilizado en Santander en diferentes épocas y tienen diferentes orígenes llegando a convivir en un topónimo “El muelle del cay”, hasta la desaparición de cay como acepción de ‘muelle’ en castellano.
Podemos ver en este mapa cómo el estudio se llevó a cabo también en la costa atlántica europea y en el mediterráneo. La 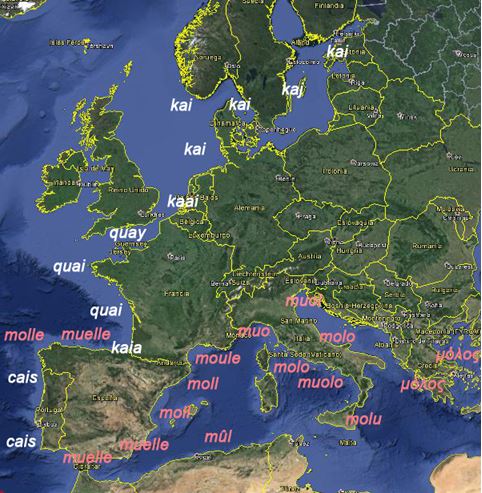 voz cay se adoptó desde el Báltico hasta el País Vasco (cay proviene del francés), mientras que a partir de Cantabria y hasta Galicia así como, en todo el Mediterráneo se adoptó muelle (que proviene del catalán), mientras que en la costa portuguesa se mantuvo la voz cay.
voz cay se adoptó desde el Báltico hasta el País Vasco (cay proviene del francés), mientras que a partir de Cantabria y hasta Galicia así como, en todo el Mediterráneo se adoptó muelle (que proviene del catalán), mientras que en la costa portuguesa se mantuvo la voz cay.
Pensemos en la ingente bibliografía que el autor debió de consultar para llegar a realizar el estudio plasmado en la obra. ¿A cuántas bibliotecas y museos tuvo que acudir para consultar la bibliografía sobre el tema? Y no sólo en España.
Ahora, supongamos que todas las bibliotecas y museos tengan publicadas las descripciones de sus fondos como un conjunto de datos en Internet bajo estándares de la web. Estos conjuntos de datos están enlazados entre ellos porque tratan de un mismo concepto. Por ejemplo; dos conjuntos de datos hablan de “Picasso”, uno de ellos sobre su obra y el otro sobre su biografía. Una máquina (un ordenador) sería capaz de leer dichos conjuntos de datos y saltar de un conjunto a otro mediante enlaces y de este modo ampliar la información al usuario.
Esto nos permitiría realizar preguntas complejas como por ejemplo “¿dónde vivía Picasso cuando incorporó la cerámica como soporte a su obra?” Tras obtener la respuesta, en este caso “Antibes (Francia)”, querremos saber más sobre esta localidad. Aquí es donde entra en juego lo que se denomina la nube de datos enlazados o Linked Data Cloud que agrupa todos esos conjuntos de datos publicados en Internet. Entre ellos existe uno denominado GeoNames que nos aportaría más información sobre Antibes y evitaría que recorriéramos webs y más webs, dejando que sean las máquinas las que hagan el trabajo por nosotros.
Ahora bien, ¿qué ocurre con la tecnología subyacente a todo esto que contamos? Si yo tengo datos para publicar no tengo porque ser experto/a en la publicación en esa nube de datos enlazados. Vamos a poner un ejemplo, la Biblioteca Nacional de Hungría fue una de las pioneras en publicar sus fondos con un conjunto de datos en esa nube que mencionamos. Al no disponer de la tecnología que permitía acelerar esa publicación tardaron tres años en tener el conjunto de datos listo para ser publicado.
La tecnología en realidad ya está lo suficientemente madura como para automatizar todo el proceso y que los propietarios de los datos no tengan que preocuparse nada más que de seleccionar qué quieren publicar. Con este objeto se desarrolló ALIADA.
Retomemos la primera cuestión. ¿Qué sucedería si pudiésemos consultar toda esta información conjuntamente y no tuviéramos que ir a cada web o visitar personalmente cada institución? ¡La respuesta es sencilla! Aceleraríamos la investigación y lograríamos que aparecieran nuevas innovaciones haciendo uso de estos datos que ahora son procesables directamente por máquinas.
Ahora vayamos a la segunda pregunta que nos quedó en el tintero. ¿Si pudiéramos enriquecer otra información (turismo, educación,…) con toda esta herencia cultural? Se podrían desarrollar aplicaciones que enriquecieran contenidos educativos, para facilitar el periodismo de datos, otras obtendrían contenidos culturales para visitar un lugar en base a nuestros gustos o preferencias. A medida que fueran publicándose más datos, el límite sería nuestra imaginación.
En este post nos hemos centrado en los contenidos culturales, pero en la nube de datos enlazados podemos encontrar música (last.fm, BBC Music); las proteínas (UniProt); DBpedia, Flickr; The New York Times; datos abiertos de diferentes gobiernos… etc. Todos estos conjuntos de datos enlazados forman una red navegable de máquinas dando lugar al sueño del inventor de la web Sir Tim Berners-Lee: la web de los datos.
La web que navegamos a día de hoy se denomina la web de los documentos y no está preparada para que la recorran las máquinas sino para los seres humanos. Para sacar el máximo potencial a toda la información que cada día aumenta exponencialmente en Internet necesitamos nuevos paradigmas, nuevas tecnologías que nos permitan explotar toda esta información.
Y no sólo eso, las tecnologías semánticas nos sirven para hacer interoperables datos heterogéneos, tecnología clave en ámbitos como el Big Data donde las grandes cantidades de datos heterogéneos son el principal escollo a solventar. Pero la semántica también nos es de gran utilidad en otros ámbitos donde diferentes empresas deben colaborar en tiempo real como puede ser la logística, sin olvidar el Internet de las Cosas donde diferentes sensores nos dan medidas en tiempo real de diferentes aspectos de nuestro día a día: seguridad ciudadana, nuestro hogar, la ciudad, los coches, las carreteras…
*Infografía cedida por el autor © Alberto González Rodríguez
